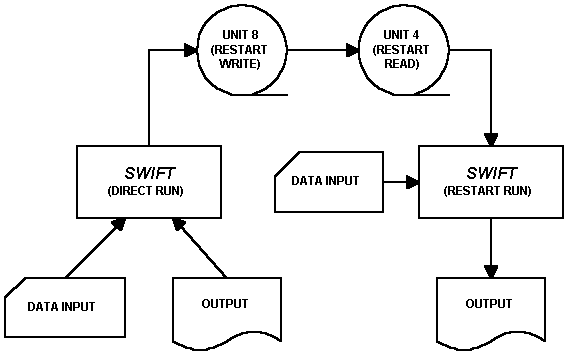
10.1 CALCULATIONAL RESTARTS
Figure 10-1 shows the basic sequence of events for restarting a calculation. As illustrated there, UNIT 8 is written during the execution of the direct run. This information is then read from UNIT 4 and the first restart run commences. Although it is not illustrated by the figure, another restart record may be written (on UNIT 8) during the second execution and the restarting process may be continued indefinitely.
Aside from the temporary-store variables, which are defined locally within each subroutine, all scalars and arrays are partitioned within the four common-block arrays. A restart procedure is initiated by simply setting the control
WRITE(8) (G3(I),I=1,IG3LST) (10-2)
WRITE(8) (G2(I),I=1,IG2LST)
WRITE(8) (G(I),I=1,IGLSTR)
WRITE(8) (IG(I),I=1,IGLSTI)
The calculation may be restarted by so indicating with the control
| UNIT | Function | Default
File Suffix |
| 4 | Input for restart calculation | .RST |
| 7 | Output for streamline postprocessing | .VL |
| 8 | Output for subsequent restart calculation | .WR |
| 9 | Output for nuclide monitor post-processing | .NM |
| 10 | Output for contouring based on mapping options | .XYZ |
| 11 | Input for heterogeneous reservoir R1-21 | .BIN |
| 12 | Input and output for plotting via SWIFT | .WL |
| 13 | Output for contour mapping using MODFLOW format | .MAP |
| 15 | Standard 80 column input | .DAT |
| 16 | Standard 132 column output for printer | .OUT |
| 17 | Output for mass balance summary | .MBL |
| 18 | Output for aquifer influence function flux values | .AIF |
Unformatted files:
- Heterogeneous reservoir (optional, see R1-21): UNIT 11.
- Contour mapping (optional) UNIT 10:
Format is formatted if LMAPIT = x1 (M-3) and unformatted if LMAPIT = x2
(M-3). Also the creation is further controlled via KMP10 (R2-14).
where ITIME indicates the time step of the particular restart record which is to be used to initialize the follow-up calculation. The code then simply reads the list of restart records written during the previous run(s) until the appropriate one is found, loads the common-block arrays and continues the calculation. A list of the appropriate data input is given in Table 10-2.
10.2 MAPPING RESTARTS
Assume that an auxiliary disk file
has been loaded with several restart records, as described in the preceding
section, and that it is desired to map the results present in some of those
records. There are options in SWIFT which permit such to be done. The configuration
is similar to that shown on the right-hand side of Figure 10-1. Thus, UNIT
4 contains the restart data which is read by the code, along with data
from records, and maps are obtained in the output. The necessary record
input is presented in Table 10-3. Basically, the function of this entire
set of input data is to search the auxiliary unit for the appropriate restart
record(s), as indicated by the time-step number(s) and then to map the
primary variables as contour plots over the specified spatial domain. Mapping
specifications may be changed from that originally given (at the time the
restart record was made) as desired.
| Card Identifier | Function |
| M-1 | Title |
| M-2 | Option Parameters (RSTRT > 0) |
| R2 Group(s) | Recurrent-Data Input |
| P Group1 | Plotting of Well Data |
| Card Identifier | Function |
| M-1 | Title |
| M-2 | Option Parameters (RSTRT = -1) |
| ---First Map from Restart Record--- | |
| M-6 | Time-Step Number (IMPT > 0) |
| M-7 | Mapping Control |
| R2-14 - R2-151 | Map Specifications |
| --Additional Maps From Restart Records2-- | |
| M-6 - R2-15 | |
| ... | |
| ... | |
| M-6 | Blank |
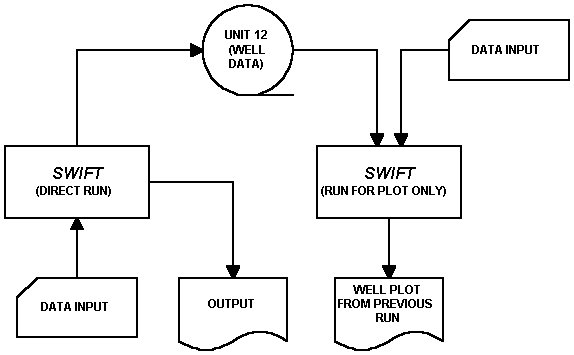
10.3 PLOTS OF WELL DATA
As in the case of mapping, plots may be obtained either at the time of a calculational run or from a separate plotting run. The purpose of this section is to elaborate on the latter. Figure 10-2 configures the case to be considered. As illustrated there, all plotting variables are written UNIT 12 by SWIFT. Providing, then, that this auxiliary file has been properly preserved, it may be attached for a plotting run.
To write UNIT 12, a formatted output statement is used, specifically in Subroutine PRINT2,
1630 FORMAT (2I5,7E12.5)
| Parameter | Alias | Definition |
| KW | I1I2 | Well Number |
| I2 | I2 | Control Number |
| TXC | U1 | Time |
| PCW | U2 | Pressure at bottom-hole |
| PCS | U3 | Pressure at surface |
| TCW | U4 | Temperature at bottom-hole |
| TCS | U5 | Temperature at surface |
| CCC | U6 | Brine concentration |
| QW | U7 | Well flow rate |
A record of the above form is written for each time step during the calculation.
In contrast to the writing of a restart record, the writing of UNIT 12 is not controlled by an integer such as RSTWR (READ R2-13). It is controlled only by the requirement that there must be wells in the system, i.e., NWT > 0. The control parameter I2 specifies the plots which are to be made. As discussed in Chapter 9 (see especially Table 9-1) the specification of plotting variables depends upon the well characteristics. Thus, only a selected number of the dependent variables of the above output list will be plotted depending upon whether the well is an injection, production or observation well and on whether surface or bottom-hole conditions are specified. Parameter I2 takes into account these factors.
The additional information necessary for plotting is that deriving from the standard input unit, i.e., the data on records. Table 10-4 characterizes this data. As illustrated, negative values of the plot controls NPLP, NPLT and NPLC are necessary to trigger the plotting from a previous run in that control is transferred immediately to the plotting routines. As many wells as desired may be used for the plotting.
The plot file ___.WL can easily be imported to a spreadsheet. The file format groups all wells for a time step, thus the data may require some rearrangement in order to develop a time series. For radionuclide discharge, it may be necessary to merge the ___.WL file with the nuclide monitor output (Section 10.8).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.4 STREAMLINE POSTPROCESSING
It is frequently helpful to present flow results in terms of streamlines. For this reason the appropriate information is written to the auxiliary file so that it may be processed by a streamline postprocessor. Figure 10-3 gives the configuration of such an operation. As shown there, UNIT 7 is prepared during the SWIFT run and is subsequently read by a streamline utility. The latter is denoted there by the acronym "STLINE."
The first record contains
the current version number.
The second record contains the depth to datum for converting between block depth and elevation.
(2) WRITE(7) HDATUM /See R1-16
The third record of information of UNIT 7 comes from the unformatted output statement:
WRITE(7) NX, NY, (DELX(I),I=1,NX), (DELY(I),J=1,NY)
(5) WRITE(7) (FR(M),M=1,NB) /Saturated block thickness
(6) WRITE(7) (PV(M),M=1,NB) /Saturated pore volume
(8) *WRITE(7) (UYY(M),M=1,NB) /y-direction Darcy velocity
(9) *WRITE(7) (UZZ(M),M=1,NB) /z-direction Darcy velocity
(10) *WRITE(7) (P(M),M=1,NB) /Fluid pressure at elevation
(11) *WRITE(7) (BW(M),M=1,NB) /Fluid density
(12) *WRITE(7) TIME /Elapsed simulation time
*For transient flow analysis, only these arrays are written at time steps 2 and thereafter.
They contain saturated block thickness, FR; pore volumes, PV; Darcy velocities, UXX, UYY and UZZ; and fluid pressure at elevation. At present, simulation times are not written, instead the writing of UNIT 7 is controlled by the integer IIPRT (see READ R2-13).
Note: All real variables
are double precision (REAL*8) and integer variables are long integers (Integer*4).
While the contour maps from the output file are invaluable in trial simulations, ultimately report quality figures will be needed. This may be accomplished by an auxiliary file and postprocess the dependent variable with other software such as SURFER, PLOT88, DISSPLA, or DI-3000. The "map" file is written to UNITs 10 and 13. The file is controlled by the options for the printer (UNIT 6) contour map (see R2-13 to R2-15).
The map data are written to two files as well as optionally being listed with the other output on UNIT 6. The ASCII file on unit 10 may be processed by entering the data as randomly-spaced input to contouring packages. Alternatively, the grid or matrix format file on unit 13 allows for post processing consistent with the U.S. Geological Survey Modular Groundwater Flow code MODFLOW (McDonald and Harbarugh, 1988). In either case, the control for writing these files is the same.
The ASCII file on UNIT 10 is a header record and a continuous string of records containing the x-coordinate, y-coordinates and dependent variable for the window of the map as specified in the R2-13 to R2-15 records. The format is:
Header Record
TIME, ITIME, (TEXT(I),I=1,3) using format (E10.3, I10, 3A4)
Triad List
Col. 1-15 16-30 31-45
X(I) Y(J) A(I,J) (3G15.7)
X() and Y() are the grid block centroid coordinates and A(I,J) is the dependent variable mapped (see MAP on R2-13). In the case of zero pore volume blocks, the value of the dependent variable will be -9999. In addition, to avoid the possibility of underflows the minimum absolute value of the dependent variable is set to 1.0 E-30.
The grid or matrix file,
written to UNIT 13, is styled after MODFLOW (McDonald and Harbaugh, 1988).
The MODFLOW file structure is adopted as a standard convention to facilitate
the postprocessing of contour maps. The UNSWIFT utility in Section 11 describes
the translation procedure to interface with SURFER7. In contrast, SWIFT
does not use stress periods, nor are the data files designed on a horizontal
layering concept. It is nevertheless worthwhile to adopt the MODFLOW format
to allow for interchangeability. The structure for the map files is:
DELT is the time step size (PERTIM)
TIME is the elapsed simulation time (TOTIM)
TEXT is the 16 character description of the dependent variable (TEXT) [Declared CHARACTER TEXT(4)*4]
NC is the number or columns or x-increments (NC)
NR is the number of rows or y-increments (NR)
KK is a slice index in SWIFT, but refers the layer number in MODFLOW (ILAY)
For areal maps KK is the layer, counting downwards from the top most. For cross-sectional maps, KK is the slice index, e.g. for an X-Z map, KK refers to the y-index slice number.
10.6 MASS BALANCE SUMMARY
It is convenient to have the mass balance at each time step summarized in a separate table. At each time step the program writes a record to UNIT 17 including the time step number, elapsed simulation time, time step and mass balances for pressure, heat, brine, unleached nuclide, leached but not dissolved nuclide, dissolved nuclide and nuclide in the matrix subsystem. The output is controlled by LMBAL on record M-2.
10.7 HETEROGENEOUS RESERVOIR SPECIFICATION
The heterogeneous reservoir specifications allows for a separate file to control the hydraulic parameters and grid definition otherwise input on record R1-21. The heterogeneous reservoir file in a binary file which contains the block-by-block values of hydraulic conductivity, porosity, depth, thickness and heat capacity. This option is preferred over the record-based R1-21 for situations in which values vary from block to block. The R1-21 is best suited for zonal-based applications.
The heterogeneous reservoir file can be created through contouring or Kriging of site data. This file is substantially more compact than using the formatted R1-21 style which can reach several megabytes. Furthermore, the file is stored separately thus allowing easier editing of the primary data input file.
The heterogeneous reservoir
option is invoked by entering a negative value (i.e., -1) for I1 in the
R1-21 record. The code then requests the file name containing the heterogeneous
reservoir data. The contents of this file are:
or
KX (M), M = 1, NB /x-Hydraulic
conductivity
KY (M), M = 1, NB /y-Hydraulic
conductivity
KZ (M), M = 1, NB /z-Hydraulic
conductivity
PHI (M), M = 1, NB
/Porosity
UH (M), M = 1, NB /Depth
(positive downwards)
UTH (M), M = 1, NB
/Block Thickness
UCPR (M), M = 1, NB
/Heat capacity
There is no error checking on the length or contents of the arrays. While this provides a convenient means to include heterogeneity, the user should verify the contents of the binary file (i.e., KOUT=0, M-3; IIPRT = 12, R2-13). The use of a window option is recommended (M-3 and R2-16).
10.8 NUCLIDE MONITOR BLOCK
The radionuclide concentration at selected block (see Section 7) are written to UNIT 9 at each time step for postprocessing. This provides a time series of the nuclide mass fraction. The calculated concentration values may, for example, be multiplied by the water mass flux rate leaving a particular block to obtain the nuclide mass discharge rate. This would be appropriate for risk assessment or possibly evaluating the performance of a remediation strategy.
The format of the nuclide
monitor file is one record for the elapsed time followed by one record
for each nuclide at each time step. In the case of multiple components,
the concentrations follow sequentially on the record starting with component
number 1. The format for each record is:
I is the component (I3)
DI() is component label (2A4)
CC(J) is the concentration
mass fraction (G11.4).
10.9 AQUIFER INFLUENCE SUMMARY
The values of flux of water, heat and brine at aquifer influence function boundary blocks are written to UNIT 18. This facilitates post processing of boundary fluxes where the user has specified prescribed values for the pressure (at elevation), temperature and brine. The output is controlled by parameter LAIF on Record M-2. At each time step the values of flux are written to the file. Auxiliary programs or spreadsheets may be used to integrate or sum the data.
The output file is in ASCII. A header record is written followed by the transient data. The format of the header record is:
2 A80 TITLEIT(I), I = 81, 160
3 4I5, 4E10.3 JABL, I, J, K, VABB(JABL) PIN(JABL), TIN(JABL), CIN(JABL) (Total of NABL records)
4 E10.3 TIME
5 10E10.3 QWSW(L), QHSW(L),
QGIS(L), (CC(L+I) *QWSW(L), I=1, NCP) (Total of NABL records)